Building the Right Product
I shot an interview with Adolfo Foronda about building the right product as a product owner. Check it out! Click “Continue reading” below for my speaking notes, which are an approximate transcript.
I shot an interview with Adolfo Foronda about building the right product as a product owner. Check it out! Click “Continue reading” below for my speaking notes, which are an approximate transcript.
I shot an interview with Adolfo Foronda about saying “no” as a product owner. Check it out! Click “Continue reading” below for an approximate transcript.

I recently came across Mark Graban‘s “Highlights from the Original 1984 NUMMI Team Member Handbook” series. Digging through the archives at Ephlin’s UAW office papers were archived at the Walter P. Reuther Library at Wayne State University in Detroit, Mark found some absolutely extraordinary gems, including this one.
Standing on the shoulders of giants, I reached out to the archivists at the library to see if I could get a copy of the full handbook. They cheerfully obliged, and rather quickly at that!
Grab the PDF and peruse for yourself. The first several pages are the most interesting, but even as you explore the rest of it pay attention to how human and reasonable it is. Mark provides an excellent commentary on several key sections, so I’ll try to avoid highlighting the same thoughts. I hope you’ll share your own findings and commentary in the comments below.
Here are some of the gems I’ve found:

Notice that the first objective is “To help [employees] develop to [their] full potential.” In fact, these objectives start with the individual employee, progress to the company, and then ultimately end with the customer receiving the “highest quality automobiles in the world.” This is a notable inversion from the usual objectives, which usually prioritize stakeholders and customers, then the company, then—if at all—the individual employee.
This is extraordinary in two ways. First, employees are given the expectation that they are going to have a greater autonomy and influence over how other aspects of the organization operate. I’ve heard the statistic that Toyota’s 300,000 global employees make a total of one million suggestions annually, 97% of which are implemented. Secondly, note that the employee handbook is characterized as helping the employee “do [their] job better,” a far cry from the usual purpose of this kind of handbook (protecting the company’s interest).

A team should be able to complete 80–110% of their planned stories each and every sprint without heroics.
Why is this important?
If a team regularly completes less than 80% of their sprint objectives, why does this happen?
It’s not always easy to glean these issues from tools like Rally. Thankfully, there’s a simple solution that can help both individual teams and the program discover the severity and nature of the issues that prevent a team from achieving fast, flexible flow.
Let’s take the example of a 2-person team working a 2-week sprint. (This isn’t an ideal team setup, but it keeps the numbers easier to work with.) Here’s their sprint backlog a few hours after planning:
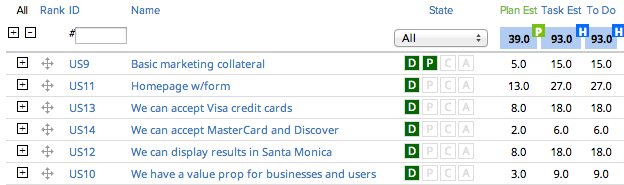
They’ve taken on 39 story points, which is one fewer than the 40 accepted story points they completed last sprint. That’s perfectly reasonable.
They’ve added tasks to each of these stories and began work on the first one.
I like to assume 6 hours/day of productivity per developer to account for planning meetings, standups, retrospectives, breaks, lunch, etc. Two developers * 2 weeks * 6 hours/day = 120 hours. Assuming a 25% “safety factor” (some teams use 30%, others use 20%, the truth is that we’re splitting hairs at this point), the team should be able to complete about 96 hours of planned tasks this sprint. They’ve identified 93, so this “smells” okay.
(Note: the team should use story points to gauge how much work to accept into the sprint backlog. Use the task hours as a sanity check.)
Let’s fast forward a week and a half. It’s Tuesday afternoon, and there are about 2-1/2 days left in the sprint:
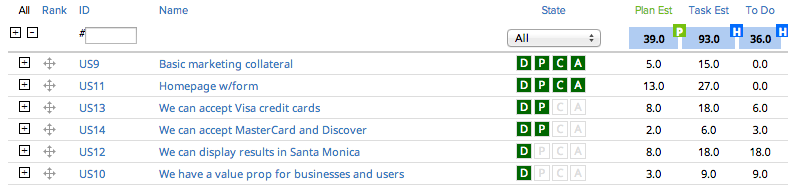
The product owner accepted 18 points or 46% of the sprint. There’s 36 hours of work left and about 30 hours of time left, so we’re a little behind. Most novice Scrum teams would not register concern at this point.
What happened during the sprint? The development team raised impediments during the standup and worked through them. One developer was out sick for a day. The team had to go to an unexpected all-hands meeting, and they had to do a couple of side projects.
The problem is, there’s no measurement or record of these unexpected requests and impediments. The unexpected requests should not have been added mid-sprint unless they were (rare) “on-fire” issues. The team (and anyone who attended the standups) would know what the issues were, but this knowledge is limited or non-existing at the program level or higher.
This is a missed learning opportunity as we do not have the transparency we need to inspect and adapt.
Let’s rewind and add a new story to the sprint backlog:
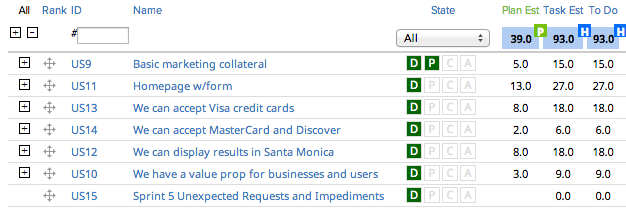
Note the addition of “Sprint 5 Unexpected Requests and Impediments” at the bottom. This doesn’t get story points and it’s at the bottom because it’s the last thing you want your team to be working on.
Each and every unexpected request or impediment gets added to this story as a task (with hours) during the sprint, like so:
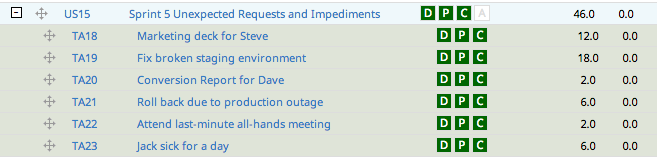
Suddenly these side projects and impediments become real.
Let’s take a look at that mid-sprint view of the backlog again.
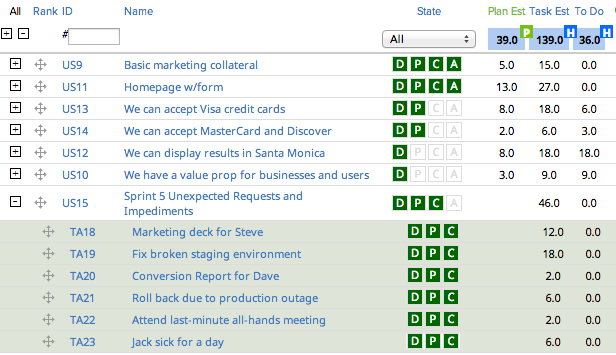
Suddenly, the problem becomes even more clear. We should be able to complete about 120 hours of work in a 2-person, 2-week sprint, but our task estimate is now up to 139. Unless this team works overtime (which they should not do as it is demotivating and ultimately productivity-killing), we’re not going to complete all of our stories in time for the demo.
So here’s where this team ended up right before their demo:
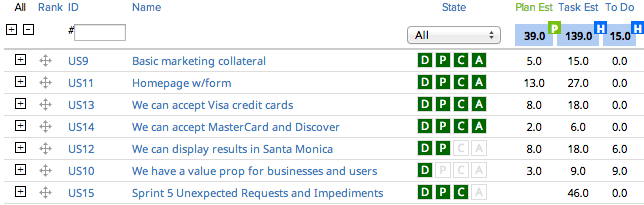
They completed 28 story points or 72%. A “pointy-haired boss” might look at this team and say “you failed.”
That statement in and of itself is a failure. It jumps to the conclusion that the team experienced a performance failure. In reality (with all credit due to Mary Poppendieck), the more likely failure is that of the original hypothesis: that the team could have completed the work in the first place. There’s a major missed opportunity: the opportunity to learn something from our system and adapt.
We budgeted 25% of our time for these sorts of issues, or 24 hours. We wound up with 46 hours of unexpected requests and impediments, 22 hours “over budget.” We had 15 hours of work remaining on the two stories we didn’t complete, so it’d be pretty reasonable to say that had it not been for those extra 22 hours of work, we would have completed this sprint (and perhaps even added a 1- or 2-point story).
Ideally, you’re keeping track of your velocity from sprint to sprint. Add another metric: keep track of the percentage of task hours each sprint that came from unexpected requests and impediments.
Now we have transparency. Transparency allows inspection, inspection allows adaptation. Here are some ways to use this information to inspect and adapt:
There you have it. Regardless of the software you use (if any), you can add the Unexpected Requests and Impediments story to your sprint backlog. You can use the data it generates to gain knowledge and take corrective action.
What are your thoughts? Have you used something like this in your own team? Please share your thoughts!
Photo from Kyle Pearson on flickr

I’ve been coaching the StubHub Labs team on Agile, Scrum, and Kanban principles and practices since last July ’13. They got a nice shout-out on eBay’s corporate blog yesterday…

One of the things that I think holds Scrum teams back from being successful is that they often learn about the Scrum process but don’t learn about Agile culture or infrastructure. Because Scrum is a system that relies on all of it’s parts, failure to master Agile culture and infrastructure means that companies will also fail to master Scrum. This failure is unbelievably costly for companies and teams: “average” teams deliver only a 35% improvement over Waterfall, while properly coached teams deliver 300-400% improvements. I’ve seen this myself in my time working with Scrum teams at Atomic Online: once a team got properly coached and running, we were at least 3-4x as fast as when we started. This is rare, too: I have not yet worked with a team that has outperformed the teams I worked with at Atomic Online.
I think we owe it to ourselves as members of Scrum team to learn about and embrace Agile principles. This is hard to do without a “sensei” (a well-experienced Agile leader) who can can conduct gemba walks with incumbent leadership to bring about organizational transformation. In lieu of that, though, here are some resources that I hope can help to at least illustrate the difference between a true Agile/Scrum/Kanban environment and a waterfall environment that has adopted a few Scrum processes.

A couple of years ago, my former manager David Denton forwarded me a recorded presentation by Mary Poppendieck, a leading Agile software development expert and co-author of the popular book “Leading Lean Software Development: Results Are not the Point.”
Watching the video on the InfoQ website is a bit kludgey and Mary has lots of wonderful details that are worth hearing. So, with Mary’s permission, I’ve had the video transcribed and included her slides in context. I hope that this will make this very useful knowledge easier to find and learn from. Mary, thanks again.
I’ve eschewed block-quote formatting as it made this transcript a little harder to read. I’ve also edited slightly for readability. Otherwise, everything beyond this point is Mary’s work.